unit 3.0 - Transformers basics
Here we describe the main point of innovation of Transformers neural networks. The first paper on Transformers is here.
In a linear layer (and similarly in a convolutional layer) all inputs have a fixed pre-defined positions. Weight associated with each inputs also thus have a fixed position, since they refer to specific inputs.
For example in this figure above attributes like Color, Size, Shape etc are in specific and fixed positions.
But for some special kind of data, as for example in sentences or arbitrary sequences, inputs position may vary. Because the same sentence can be: “Terrible the day was” or “the day was terrible” or “it was a terrible day”
Here is another example of a similar sentence
If we want to judge whether the above sentences are positive or negative, we cannot rely on a fixed position of specific word that help us to identify the sentence sentiment.
In a classic explanation of this we can see a more complex sentence here. What does the word “it” refer to? It can refer to basically any word in the sentence at any positions. Here in particular it may refer to a noun in the sentence.
Clearly a linear layer is not able by itself to adapt to all these possible combinations. One could use multiple linear layer in parallel for all possible combinations, but this would be a quadratic number of linear layer proportional to the length of the sentence in words. We need something better…
The main idea of Transformers is to use an “attention layer” that can re-arrange the input sequence in a way that another linear layer will find sentence features always in the same position, reshuffling the sentence to be ready for processing.
This is done with an attention mechanism that gives less importance to part of the sentence (words) that are not relevant and more weight to words that are.
If we take the previous figure and replace the modules with linear layers, we can see how attention can be implemented.
This is a single-headed attention module that is used heavily in the Transformer. The Transformer uses 2 of such layers and 2 conventional linear layers for each of its own layers. Attention is applied multiple times both in sequence and in parallel. Multiple single-headed attention act in parallel to form a multi-headed attention module.
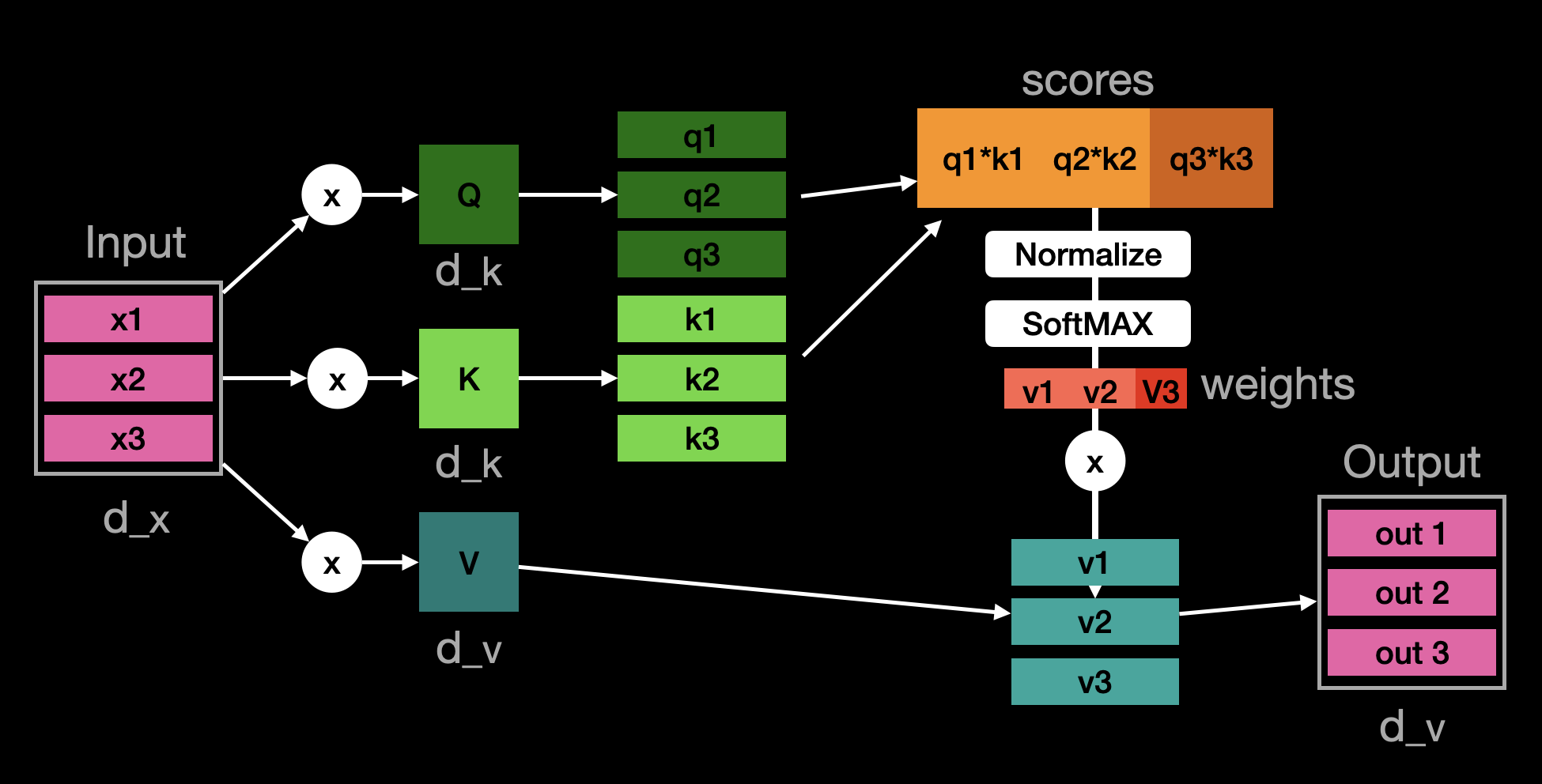
This is another depiction of the linear algebra transformation in a single-headed attention module:
This module uses 3x linear layers (matrices) to re-arrange the inputs and also a combination of these to weight in the input sentence, thus giving more or less importance to individual words.
Note that in a Transformer part of words can be used to better represent language, or “tokens”. For example tokens can be “great” and “ness” and “er”, parts that can then compose more words “great-ness”, “great-er”
Also note that large Transformer are also called GPT (generative pre-trained transformers) and LLM (large language models). The original Transformer paper was designed as an encoder and a decoder and was targeting the application of language translation.
But an encoder or decoder can both be used as a language classifier and a language model.